
西安中心













 AI智能应用开发
AI智能应用开发 AI大模型开发
AI大模型开发 AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+
AI嵌入式+ AI大数据开发
AI大数据开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作运营
AI视频创作运营
免费领取黑马程序员AI通道专属星级课程资料

更新时间:2023-08-29 来源:黑马程序员 浏览量:

数据集中的数据类型有很多种,除了连续的特征变量之外,最常见的就是类别型的数据了,比如人的性别、学历、爱好等,这些数据类型都不能用连续的变量来表示,而是用分类的数据来表示。 Seaborn针对分类数据提供了专门的可视化函数,这些函数大致可以分为如下三种:
分类数据散点图: swarmplot()与 stripplot()。
类数据的分布图: boxplot() 与 violinplot()。
分类数据的统计估算图:barplot() 与 pointplot()。
下面使用stripplot()来画类别散点图,stripplot()函数的语法格式如下。
seaborn.stripplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None, jitter=False)
上述函数中常用参数的含义如下
(1) x,y,hue:用于绘制长格式数据的输入。
(2) data:用于绘制的数据集。如果x和y不存在,则它将作为宽格式,否则将作为长格式。
(3) jitter:表示抖动的程度(仅沿类別轴)。当很多数据点重叠时,可以指定抖动的数量或者设为Tue使用默认值。
为了让大家更好地理解,接下来,通过 stripplot()函数绘制一个散点图,示例代码如下。
# 获取tips数据
tips = sns.load_dataset("tips")
sns.stripplot(x="day", y="total_bill", data=tips)运行结果如下图所示。
从上图中可以看出,图表中的横坐标是分类的数据,而且一些数据点会互相重叠,不易于观察。为了解决这个问题,可以在调用striplot()函数时传入jitter参数,以调整横坐标的位置,改后的示例代码如下。
sns.stripplot(x="day", y="total_bill", data=tips, jitter=True)
运行结果如下图所示。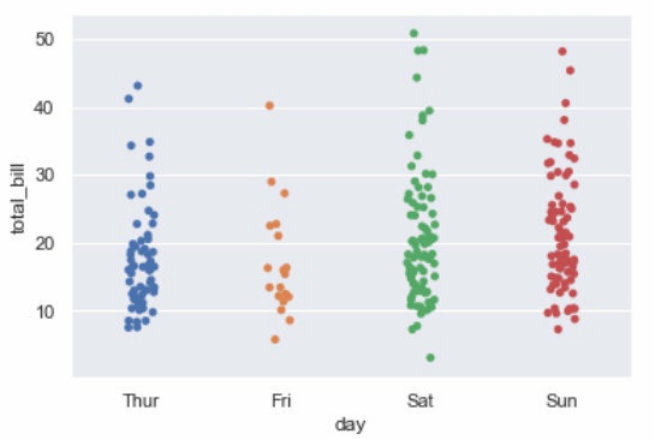
除此之外,还可调用 swarmplot0函数绘制散点图,该函数的好处是所有的数据点都不会重叠,可以很清晰地观察到数据的分布情况,示例代码如下。
sns.swarmplot(x="day", y="total_bill", data=tips)
运行结果如图所示。





















.jpg)